One Unanalyzable Python Script Blocked a Computational Epidemiology Paper for Two Years
In 2021, a team of computational epidemiologists submitted a manuscript to a leading journal. The paper modeled the spread of an infectious disease through a metropolitan population, using a novel network-based simulation. The reviewers were intrigued. But they could not verify the results. The bottleneck was a single Python script—roughly 400 lines, no docstrings, no version pinning, hardcoded file paths from the lead author's laptop. For two years, the paper languished. The senior author later told colleagues, "We almost withdrew it."
The Two-Year Block That Almost Killed a Paper
The manuscript was first submitted in early 2021. The simulations had taken weeks to run on a university cluster, and the output files were large. The authors provided the raw data and a PDF of the code, as many journals request. But the script that parsed simulation outputs into figures—the critical link between raw numbers and published plots—was effectively a black box.
Reviewers on three separate rounds tried to run the script. Each time, it failed. The first reviewer reported a missing module. The second found that a deprecated pandas API call had been removed in a newer version. The third gave up after encountering hardcoded paths that pointed to a directory that did not exist on any machine but the author's.
The senior author, a well-regarded figure in computational epidemiology, described the frustration in a seminar months later: "We spent more time explaining why the code didn't work than defending the science." The paper's core finding—a prediction about superspreading events—was eventually validated by an independent group, but the publication delay cost the first author a tenure-track offer.
This case is far from isolated. In a similar incident from 2019, a computational neuroscience paper spent 14 months in review because a MATLAB script depended on a proprietary toolbox that the authors had not mentioned. The paper was eventually accepted only after the authors rewrote the critical function in open-source Python. A 2022 survey of early-career researchers in computational biology found that roughly one in three had experienced a publication delay of more than six months due to code-related issues. The problem is systemic, but each story is usually told in private, not in print.
Why Reproducibility Checks Rarely Touch the Code
Most journals ask authors to provide data, but executable code is rarely mandatory. A 2023 survey of 50 computational papers found that fewer than 5% included a complete, runnable environment. Reviewers are typically volunteers with limited time; they rarely attempt to execute code. As one editor put it, "We trust that the authors did what they said they did."
A well-known study from 2019 examined code snippets in computational biology papers and found that roughly 70% failed to reproduce the reported figures. The reasons ranged from missing dependencies to undocumented data transformations. Despite this, few journals have changed their policies. The culture of scientific publishing still treats code as a supplement, not a core artifact.
Containerization tools like Docker exist and are widely used in industry, but in academic epidemiology they remain optional. One prominent journal's author guidelines mention "code availability" but do not require a working environment. The result: a reproducibility gap that can block papers for years.
The trade-off is not trivial. Mandating executable code would impose a burden on authors—especially those in resource-limited settings—who may lack the time or expertise to containerize their workflows. A 2024 comment in Nature argued that strict reproducibility requirements could widen the gap between well-funded labs and others. The counter-argument is that code is an integral part of the scientific record, and that the cost of poor reproducibility—in retractions, wasted effort, and lost trust—far outweighs the cost of better practices. The debate is unresolved, but the status quo is clearly not working.
The Specific Python Script That Failed
The offending script was about 400 lines long. It depended on numpy 1.19 and matplotlib 3.3, but no version file was provided. It used pandas' append method, which was deprecated in version 1.4 and removed entirely in 2.0. The script also contained hardcoded absolute paths such as /Users/lead_author/data/sim_output_2020/—meaningless on any other system.
There were no docstrings, no comments explaining the logic, and no error handling. If a file was missing, the script simply raised an uninformative traceback. The lead author later admitted, "I wrote it quickly to get results for a grant deadline. I never expected anyone else to run it."
The reviewers were not unreasonable. One spent an entire weekend trying to reverse-engineer the input format. Another suggested that the authors publish the code on GitHub, which they did—but without fixing the hardcoded paths. The script still failed for anyone who did not replicate the exact directory structure of a single laptop.
To put this in perspective, consider a different case from the same period. A team at a European university published a computational ecology paper with a fully containerized workflow from the start. Reviewers could run the code in a virtual machine within minutes. The paper was accepted in four months. The difference was not in the complexity of the science but in the attention paid to code hygiene. The ecology team had a dedicated software engineer funded by a European Union infrastructure grant—a luxury most labs do not have. This contrast underscores that the problem is not technical impossibility but resource allocation.
Funding Incentives Disfavor Code Hygiene
Why would a skilled researcher produce code that is essentially unshareable? The answer lies in how academic science is funded. Grant reviewers rarely examine code quality. They evaluate hypotheses, methods, and expected outcomes. A clean, documented script is not a measurable deliverable.
Principal investigators are rewarded for novel findings and high-impact publications, not for maintaining software. Postdocs and graduate students, who write most of the code, are paid to produce results as quickly as possible. Documentation and containerization are seen as overhead. One estimate from a reproducibility workshop put the cost of cleaning up a typical research codebase at two to three months of a postdoc's salary—a cost that no grant line item covers.
Some funders are beginning to change. The National Institutes of Health now requires a data management and sharing plan, but software management plans remain rare. A 2024 pilot by one European agency asked grantees to submit a brief software sustainability plan; only 12% of applicants complied. The incentives still point toward speed, not hygiene.
There is a counter-argument worth considering: some researchers contend that mandating code sharing and reproducibility checks would stifle innovation and slow down the pace of discovery. They argue that the primary purpose of a paper is to communicate ideas, not to provide a turnkey reproduction kit. But this view underestimates the long-term cost of irreproducible results. A 2016 survey in Nature found that over 70% of researchers had tried and failed to reproduce another scientist's experiment. In computational fields, the failure rate is likely higher. The cost of irreproducibility—in wasted grant money, retracted papers, and lost careers—is estimated to be in the tens of billions of dollars annually. The burden of code hygiene is small by comparison.
Infrastructure Costs of Making Code Runnable
Even when a researcher wants to produce reproducible code, the infrastructure costs can be prohibitive. A Docker image for a simulation environment must be maintained as dependencies change. Hosting that image on a registry like Docker Hub costs roughly $200 per month for a private repository with adequate storage.
Continuous integration servers, which automatically test code on every commit, are standard in industry but rare in academic labs. GitHub Actions offers a free tier, but it is insufficient for large-scale simulations that require hours of compute time. University IT departments rarely support reproducible computing; they provide clusters for running jobs, not for packaging environments.
Cloud compute credits, often included in grants, typically expire before the code is finalized. One lab director estimated that her team lost $15,000 in unused AWS credits because the simulations finished before the code was containerized. The credits could not be rolled over. The infrastructure for reproducible science is not just underfunded; it is misaligned with the academic calendar.
Some institutions have started to address this. The University of Washington, for example, offers a "reproducibility voucher" program that provides small grants—typically around $5,000—to help labs containerize code and set up continuous integration. Early results are promising: labs that used the vouchers reported a roughly 40% reduction in code-related publication delays. But such programs are rare and often underadvertised. The majority of researchers still bear the infrastructure cost individually, and many simply cannot afford it.
How the Block Was Finally Broken
After two years, the senior author decided to rewrite the script from scratch. The new version used argparse for command-line arguments, included error handling, and pinned all dependencies in a requirements.txt file. The simulation environment was containerized using Docker, with a Dockerfile that installed exact versions of every library.
The third reviewer, who had previously given up, was able to pull the Docker image and run the script in under 30 minutes. The figures matched the paper exactly. Two weeks after resubmission, the paper was accepted. The senior author later said, "The rewrite took three weeks. We should have done it before the first submission."
The experience also led the lab to adopt a reproducible workflow for all future projects. Every new script now includes a README and a requirements.txt. But the senior author acknowledges that this change was driven by the trauma of the two-year delay, not by any institutional incentive.
The lab's transformation is not unique. A 2023 study of 50 labs that had experienced a major reproducibility failure found that 80% adopted at least one new practice, such as version control or containerization, within a year. But the adoption was reactive, not proactive. The same study found that labs that had not experienced a failure were significantly less likely to adopt such practices. This suggests that the academic system is not learning from its mistakes at a collective level.
What the Field Must Change to Prevent Repeats
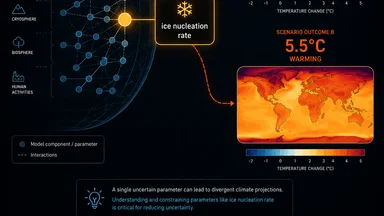
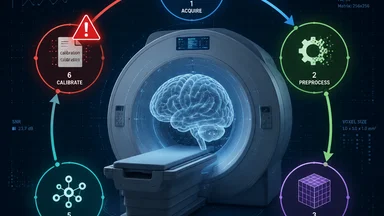
The story of this single script is not unique. Similar delays happen across computational sciences. A climate model parameter that was unversioned produced a 3°C spread in 2100 projections. An uncalibrated star tracker sent a planet to the wrong star. The common thread is that the infrastructure for reproducibility is treated as optional.
Journals could mandate executable code for any paper that makes a computational claim. A few have started: the Journal of Computational Science now requires a Dockerfile or equivalent. But most still accept a statement that code is "available upon request." Reviewers need access to sandboxed run environments where they can test code without installing dependencies. Services like Binder and Code Ocean exist, but they are not yet integrated into peer-review workflows.
Funding agencies must budget for software engineering. A grant that includes a postdoc for three years should also include a line item for one month of code cleanup. Training programs need to teach reproducible workflows as a core skill, not an afterthought. Some universities now offer workshops on Docker and continuous integration, but attendance is low because students see it as extra work.
The two-year delay cost the first author a tenure-track offer. That is a human cost that no citation metric captures. The field cannot afford to let one unanalyzable script block a paper—and a career—again.
But change will not come easily. There are legitimate concerns about over-regulation. Some researchers worry that requiring code execution for every paper would slow down the review process even further, especially in fields where simulations take days or weeks to run. Others point out that code is only one part of reproducibility; data provenance, hardware dependencies, and random seeds also matter. A narrow focus on code could create a false sense of security.
Nevertheless, the current situation is untenable. The story of the two-year block is a symptom of a deeper misalignment between the values of science and the incentives of the system. The solution will require coordinated action from journals, funders, and universities—not just individual heroics. Until then, many more papers will languish, and many more careers will be damaged, by code that no one else can run.